
How to Build a Lead Scoring Model That Sales Actually Trusts

If your sales team has stopped working your MQL queue, the lead scoring model isn't a marketing problem. It's a trust problem.
The Queue Nobody Is Working
Here's the scenario that plays out in almost every mid-market B2B company at some point.
Marketing builds a lead scoring model. Sets thresholds. Sends MQLs to sales. Sales works the queue for a few weeks, finds most of the leads aren't worth calling, and quietly stops working it. Marketing notices MQL-to-SQL conversion declining and concludes sales isn't following up properly. Sales concludes marketing's leads are low quality. The argument that follows is both predictable and unresolvable — because both sides are partially right and neither is addressing the actual problem.
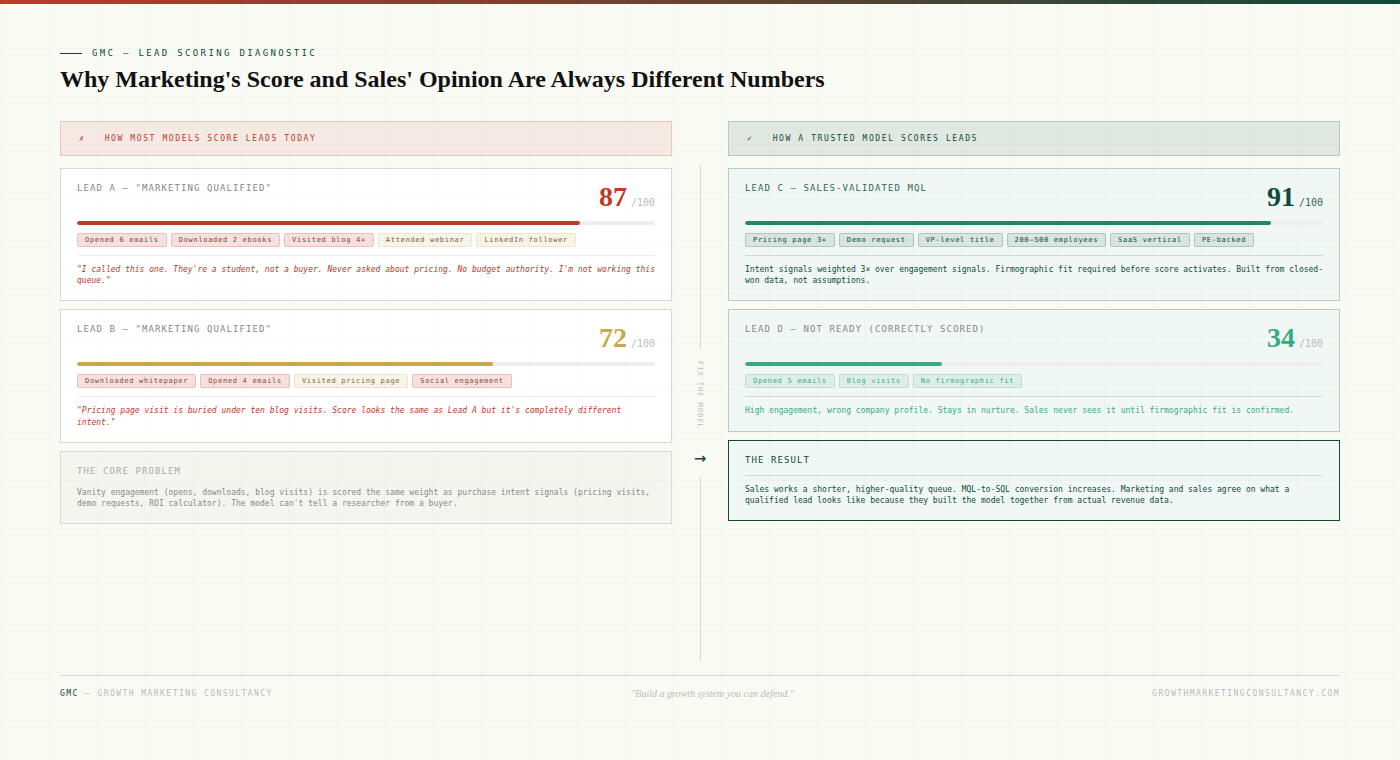
The actual problem is that the scoring model was built on assumptions instead of evidence. It scores engagement signals — email opens, content downloads, blog visits — as if they were purchase intent signals. A researcher who reads ten articles scores higher than a VP who visited the pricing page twice. Sales calls the researcher, finds no budget and no urgency, and stops trusting the queue.
This is not a technology problem. It's a model design problem. And it's fixable in five steps — if you're willing to do the uncomfortable thing and build it with sales rather than for them.
Why Most Lead Scoring Models Fail
There are three structural failures in most lead scoring models that cause sales to abandon them. Understanding all three is necessary before rebuilding.
Failure 1: Engagement and intent are weighted equally.
Engagement signals — email opens, content downloads, social interactions, blog visits — tell you someone is interested. Intent signals — pricing page visits, demo requests, ROI calculator completions, competitor comparison pages — tell you someone is evaluating a purchase. These are categorically different signals. When they're scored with similar weights, the model produces high scores for engaged researchers and low scores for quiet buyers who went straight to the pricing page. Sales learns this pattern quickly and stops trusting the output.
The fix is structural: intent signals should be weighted three to five times higher than engagement signals. And any lead that hasn't demonstrated at least one clear intent signal should not be able to reach MQL threshold regardless of engagement volume.
Failure 2: Firmographic fit isn't a gate — it's a dimension.
Most models include firmographic criteria — company size, industry, revenue band — as scored dimensions that contribute to total score. This means a perfectly fitting company with zero intent scores lower than a misfit company with high engagement. The wrong company can become an MQL purely through content consumption.
The fix is to treat firmographic fit as a gate, not a score. Before a lead's behavioural score even activates, the company must meet the ICP criteria. A lead from the wrong company type should stay in nurture indefinitely, regardless of how engaged they are. Sales should never see it.
Failure 3: The model wasn't built from revenue data.
Most models are built from a combination of intuition, competitor observation, and HubSpot defaults. Nobody pulled the last 90 days of closed-won deals and asked: what signals appeared in the 30 days before these converted? That analysis — which takes about two hours — is the most valuable thing you can do before setting a single score weight. The signals that appear in closed-won data are empirical. Everything else is a guess.
The Five-Step Framework
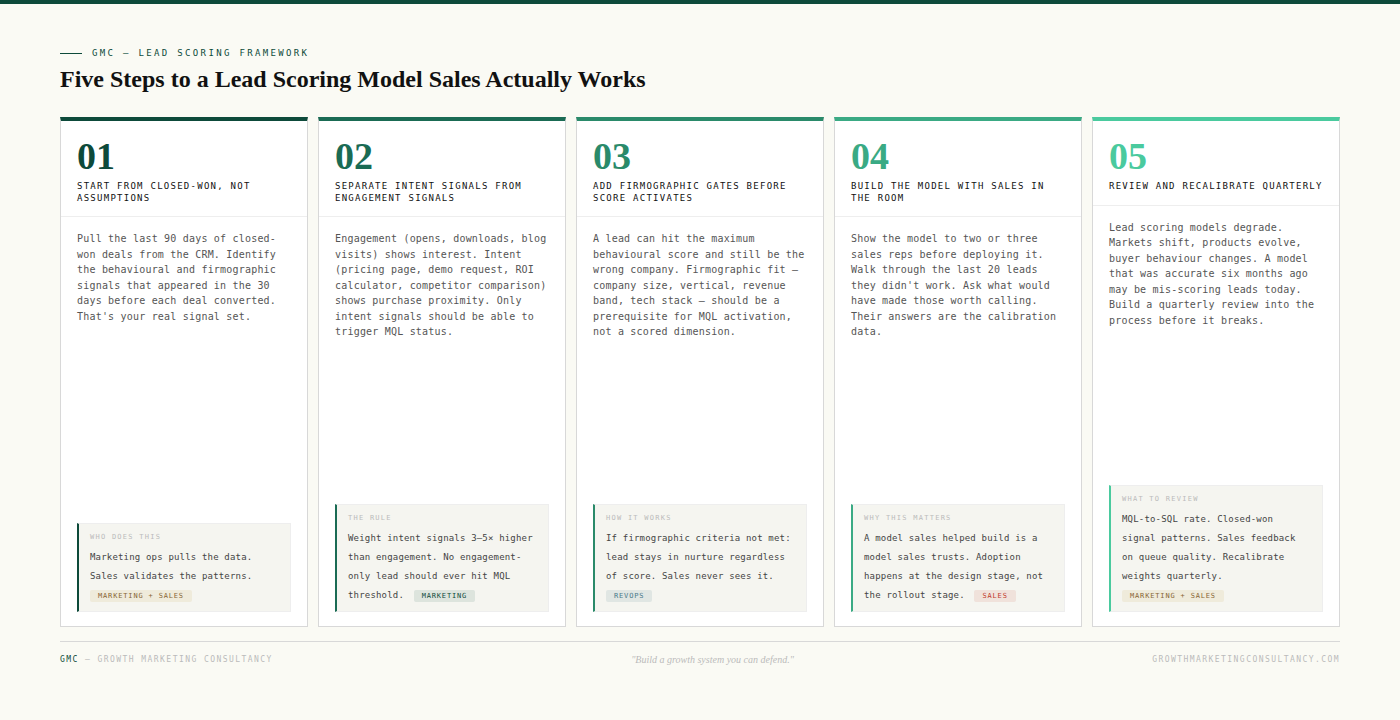
Step 1: Start from closed-won data, not assumptions.
Pull the last 90 days of closed-won deals from your CRM. For each deal, look at what behavioural signals the contact demonstrated in the 30 days before they converted. What pages did they visit? What content did they download? Did they request a demo or visit pricing? How many touches occurred before they became active?
Do this for 20 to 30 deals. The patterns that appear consistently across multiple closed-won accounts are your signal set. Everything else is noise that's been inflating scores and degrading queue quality.
This step requires access to your CRM and your marketing automation platform at the same time. Marketing ops should pull the data. Sales should be in the room when you review it.
Step 2: Separate intent signals from engagement signals, then weight accordingly.
Take the signal set from step one and categorise each signal as engagement or intent. Engagement signals are things that show interest: email opens, blog visits, content downloads, social interactions. Intent signals are things that show purchase proximity: pricing page visits, demo requests, ROI calculators, competitive comparison pages, return visits to product pages within a short window.
Assign intent signals a weight of 15 to 25 points each. Assign engagement signals a weight of 2 to 5 points each. Set your MQL threshold such that a lead cannot reach it through engagement alone — they must demonstrate at least one intent signal. This single change will do more for MQL quality than any other adjustment you can make.
Step 3: Add firmographic gates before score activation.
Define your ICP firmographic criteria precisely: company size range, industry verticals, revenue band, geographic focus, tech stack indicators if available. These criteria should be non-negotiable gates — if a lead doesn't meet them, their behavioural score doesn't activate and they don't reach marketing's radar as an MQL candidate.
Build this as an AND condition, not a scored dimension. Firmographic fit is required, not helpful. The operational effect is that sales only ever sees leads from companies that actually match the ICP. This is often the single change that most immediately rebuilds trust.
Step 4: Build the model with sales in the room.
Before you deploy anything, show the draft model to two or three of your most experienced sales reps. Walk through the signal weights, the firmographic gates, and the threshold you've set. Then do something counterintuitive: pull the last 20 leads they didn't work and ask them to tell you what was wrong with each one.
Their answers will calibrate your model better than any A/B test. You'll hear things like "this person was from a ten-person startup, we can't sell to that" (firmographic gate needs tightening), or "this one had a high score but never visited any of our product pages" (intent weighting needs adjusting). These are model calibration data, not complaints.
The deeper reason to do this step is not just calibration. It's adoption. A model that sales helped build is a model sales trusts. Adoption happens at the design stage, not the rollout stage. If sales wasn't involved in building it, they will never fully trust it.
Step 5: Review and recalibrate quarterly.
Lead scoring models degrade. Buyer behaviour changes. Product positioning evolves. Competitors enter or exit. A model that accurately predicted MQL quality six months ago may be mis-scoring leads today because the signals that indicated intent have shifted.
Build a quarterly review into the process: look at MQL-to-SQL conversion rate over the prior 90 days, review closed-won signal patterns again, and get verbal feedback from sales on queue quality. Make adjustments before the model breaks visibly, not after.
What to Expect After the Rebuild
The most immediate change after rebuilding a scoring model with this framework is a reduction in MQL volume. This is correct and expected — and it will feel alarming to anyone whose performance metrics are tied to MQL quantity.
The second change, which typically follows within 60 days, is an increase in MQL-to-SQL conversion rate. Sales starts working the queue again because the quality is demonstrably higher. Conversations happen faster. Deals that enter the pipeline from marketing-sourced leads close at a higher rate.
The third change is the most valuable: the argument stops. When marketing and sales are operating from the same model — one they built together from actual revenue data — the "leads are bad" conversation becomes much harder to have. Either the data supports the critique or it doesn't. That shift from opinion to evidence is what actually resolves the political dynami
The Conversation to Have Before You Start
One more thing before you rebuild the model. Have a direct conversation with your head of sales — not an email, a 30-minute meeting — where you ask two questions.
First: of the last 20 MQLs we sent you, how many were worth calling? Not how many converted — how many were worth the time it took to evaluate them.
Second: if you could describe the perfect MQL in specific, observable terms — not "strategic fit" but actual signals you could see in a CRM — what would it look like?
The answers to those two questions are the brief for the rebuild. Everything else in this framework is the method for executing against that brief.
Growth Marketing Consultancy builds unified GTM systems for PE-backed and founder-led mid-market companies. If your MQL-to-SQL conversion is declining and sales has stopped trusting the queue, book a Growth System Audit.